Hej,
nigdy nie miałem z tym do czynienia wcześniej dlatego postanowiłem zasięgnąć rady tutaj na forum.
Aplikacja, którą rozwijam stała dotychczas na jednym VPSie znajdującym się w zachodniej europie. Było na nim wszystko - nginx, aplikacja ror, postgres. Aplikacja jednak zaczęła być używana w stanach (i w przyszłości w azji) i dostałem zadanie poprawienia szybkości (i niezadowności - aktualnie jeśli VPS pada to wszystko przestaje działać - to jest pierwszy problem do rozwiązania) appki na innych kontynentach.
Przeczytałem wszystko co udało mi się na ten temat znaleźć dlatego spiszę moje przemyślenia poniżej. Pierwszy scenariusz ma za zadanie jedynie upewnić mnie czy dobrze kombinuję. Drugi to już mój aktualny problem.
1. Niezawodność
Aktualnie wszystko znajduje się na jednym VPSie więc jeśli serwer pada albo jeden z jego elementów (np. postgres - chociaż głównym problemem są pady aplikacji ror więc na nich się skupie) pada, to cała aplikacja leży i nie można jej używać. Jeśli był by to mój główny problem, to rozwiązał bym go w następujący sposób:
a) Podzielił infrastrukturę na trzy serwery w tym samym data center: dwa (albo więcej, w zależności od potrzeb) na aplikacje i jeden na bazę danych
b) Podpiął bym te dwie aplikacje do bazy danych znajdującej się na trzecim serwerze
c) przed dwoma(+) serwerami z appkami postawił bym load balancera, który przekierowywał by ruch do odpowiedniego z nich.
Czy tak rozwiązuje się tego typu problem?
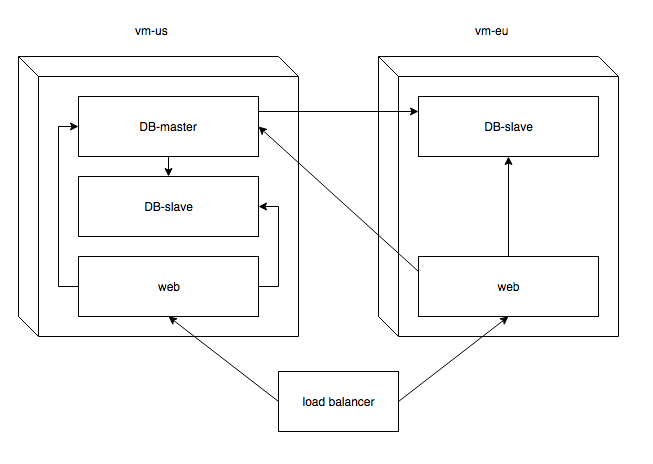
2. Dostępność na różnych kontynentach.
Jeśli kolejnym krokiem była by poprawa dostępności na różnych kontynentach, to oczywiście nie mógł bym po prostu stawiać każdej nowej maszyny z appką na innym kontynencie bo profit z bliskości do maszyny z appką był by niwelowany przez odległość od appki do bazy danych. Oto jak rozwiązał bym powyższą sytuację:
a) load balancer przed appkami rozdzielający ruch na podstawie odległości klienta do serwerów
b) na każdy region po dwie maszyny - jedna z appką i jedna z bazą danych
c) (tutaj zaczyna się gdybanie) jeden dodatkowy serwer z “centralną” bazą danych, który synchronizował by dane pomiędzy sobą a bazami danych w poszczególnych regionach.
Nie mam pojęcia jak rozwiązać problem baz danych w różnych regionach i cyz punkt c ma sens. Jeśli tak, to gdzie powinien znaleźć się główny serwer bazy danych? Czy mam pewność, że synchronizacja mi się nie rozjedzie? Jest to bezpieczne rozwiązanie? Czy postgreSQL dostarcza jakichś wbudowanych narzędzi do tego typu rozwiązań?
Jestem w temacie zupełnie zielony a wykonać to muszę więc będę dozgonnie wdzięczny za wszelaką pomoc i wskazówki : )
ps. szukam możliwie najprostszego wyjścia z sytuacji

 Jak macie jakieś pytania to piszcie śmiało.
Jak macie jakieś pytania to piszcie śmiało. Dobrze wiedzieć, że istnieje taka usługa w Azure.
Dobrze wiedzieć, że istnieje taka usługa w Azure.